Pre-Reading
In our daily use of social media, we input data about ourselves through digital interfaces. These data form our own stories in cyberspace through algorithms, and we construct a digital identity for ourselves. This identity may be carefully designed for ourselves, or it may be revealed inadvertently. To some extent, the identity formed based on the algorithm may be more real than the real you. Additionally, our algorithmic identities change dynamically over time because algorithmic identities are fluid, what we do in cyberspace, how long we spend it, who our friends are, what their preferences are...
At the same time, we also need to seriously think about how the algorithms in the platform will understand us based on the data we input and what impact it will have on us. This is also a possible reason for the existence of digital divide and digital inequality.
Sumpter, D. 2018. The Principal Components of Friendship. In: Outnumbered: From Facebook and Google to Fake News and Filter-Bubbles: The Algorithms That Control Our Lives. London: Bloomsbury, pp. 14-17.
Cheney-Lippold, J. 2011. A New Algorithmic Identity: Soft Biopolitics and the Modulation of Control. Theory, Culture & Society. 28(6), pp. 164-181.
Burnham, B. 2021. White Woman’s Instagram – Bo Burham. YouTube.
Input
What data of us can be collected by platforms and their algorithms?
(1)Content we shared: audio, video, images, etc
(2)Demographics
(3)Location Details
(4)Search queries
(5)Browsing files: cookies and trackers
(6)Biometric data: fingerprint, facial details, etc
Output
As put into social media sites, our information and data are being processed in some way, and it is hard to work out how it is being processed. One place we can start is by looking at the ‘output’ of these algorithms.
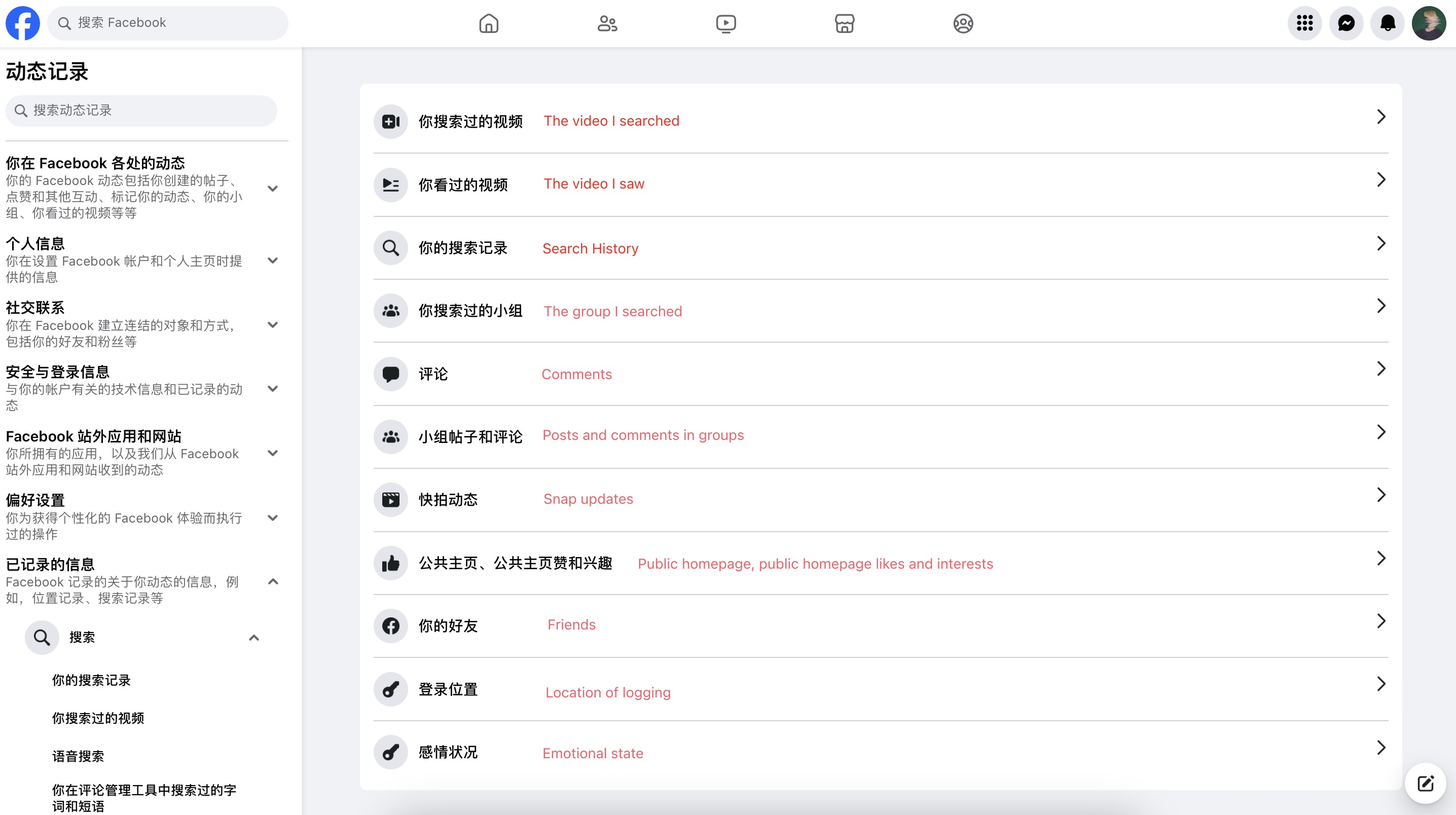
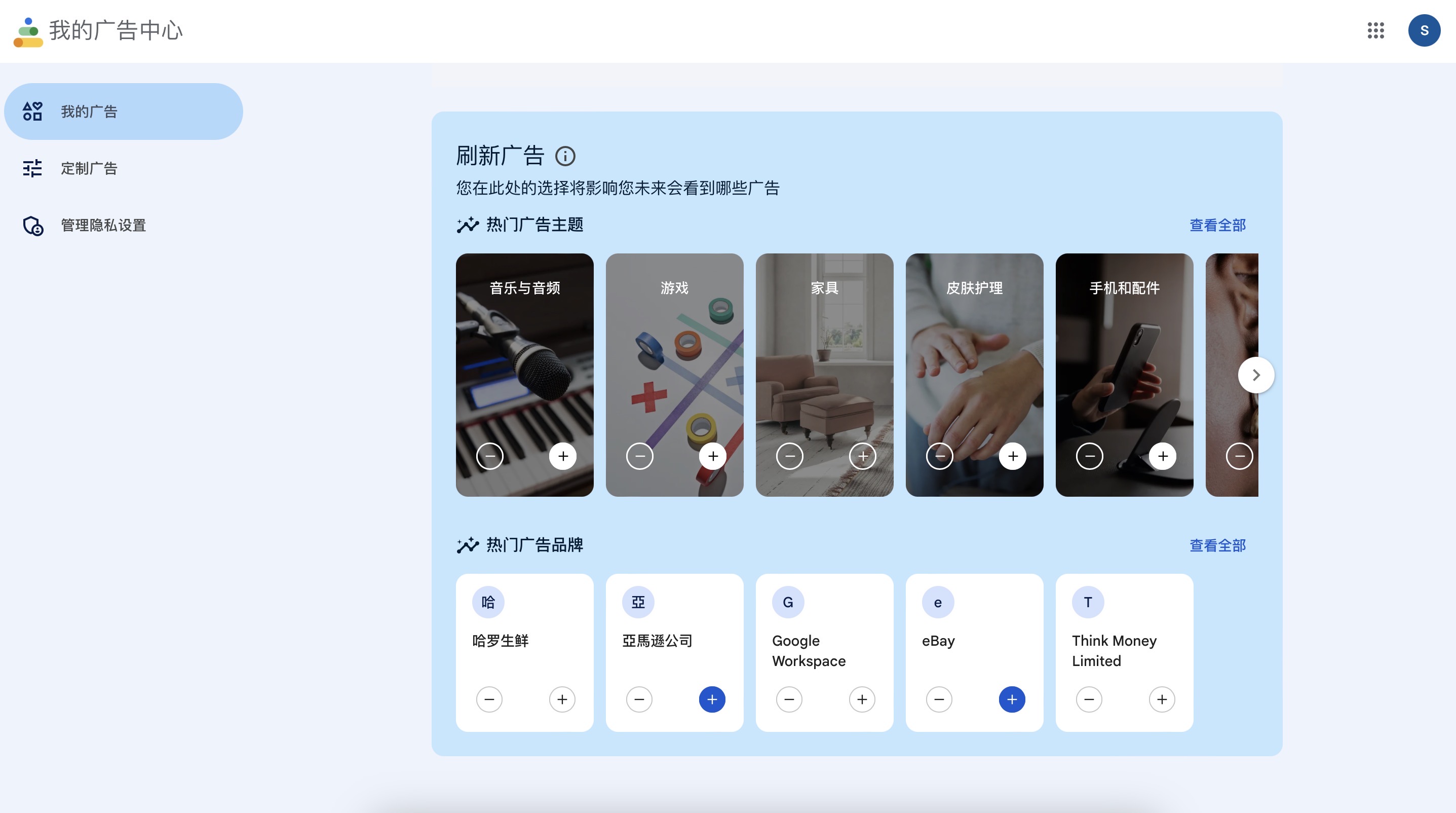
Companies now give us some information about the profiles it creates in relation to us. This is due to the growing concern people have over web tracking.For example, Facebook translates millions of bits of activity into a few hundred components; this is done through algorithmic pattern recognition. You can find out how the company has characterised you by accessing the 'Privacy Centre' again.
Just Look at: https://adssettings.google.com/authenticated
The way Ads are served to you - output based on your profile
The way you are used to build AI models...
My ads center in Google
Process
David Sumpter's 2018 book Outnumbered proposed an experiment that mimics how social media platforms work. We can choose Facebook, Instagram, Weibo or any other social media account: the important factor that remains the same is the numbers.
Get Sumpter Matrix Template from the link
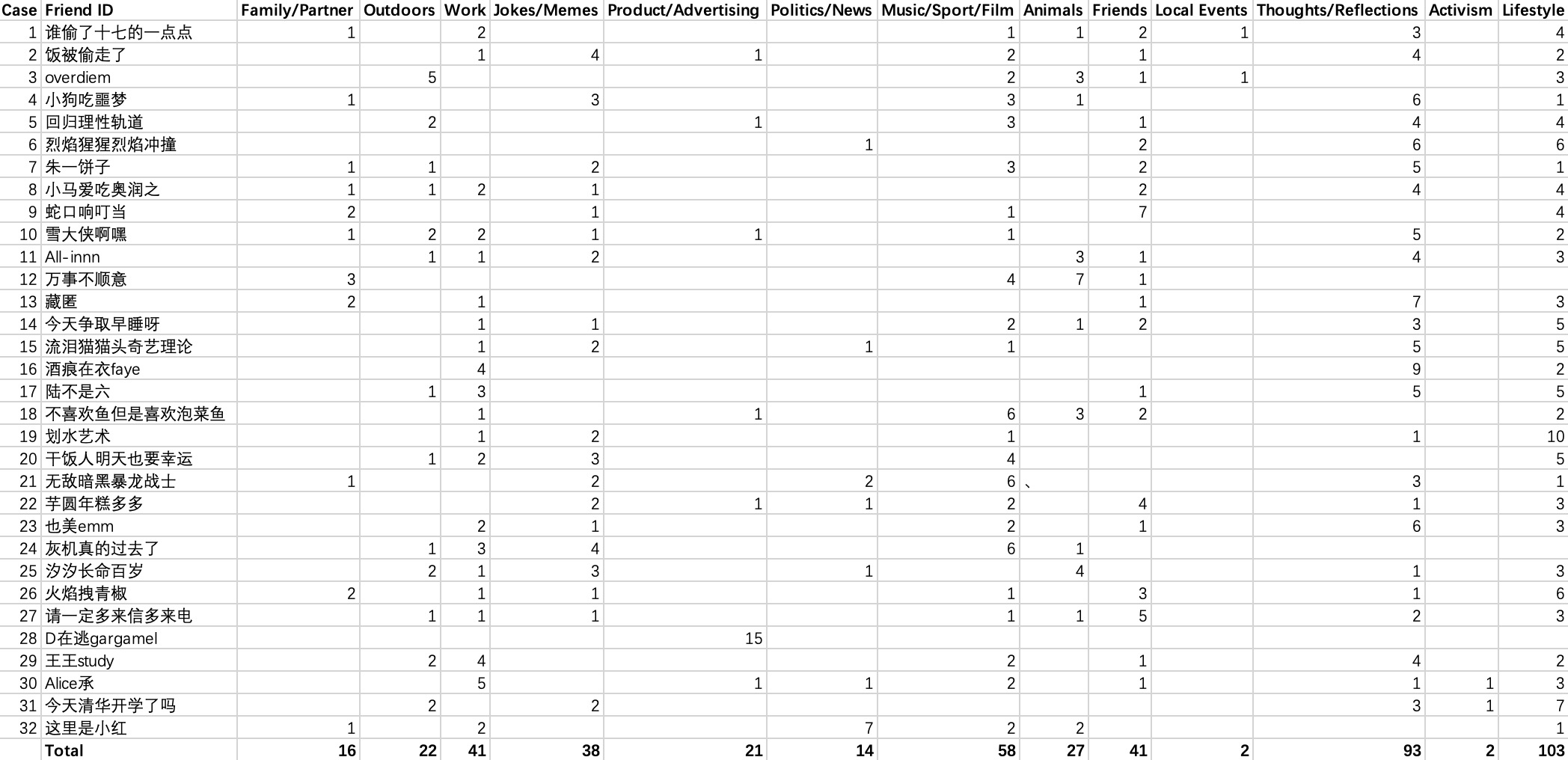
Step 1: Choose 32 of your friends on the platform of your choice (just don't use WhatsApp or WeChat because these count differently). Choose the last 15 posts from each person.
Step 2: Create a spreadsheet with the following 13 categories: family/partner; outdoors; work; jokes/memes; product/advertising; politics/news; music/sport/film; animals; friends; local events; thoughts/reflections; activism; and lifestyle. To make your life a bit easier, consider using the template that we've made for you (linked above).
Step 3: You need to put each of the last 15 posts into ONE category (so each person has 15 entries). You can’t put one post into two categories. In your spreadsheet, give one point for each post.
Step 4: Then, create between 3-5 graphs with 2D axes, plotting two of the categories against one another.
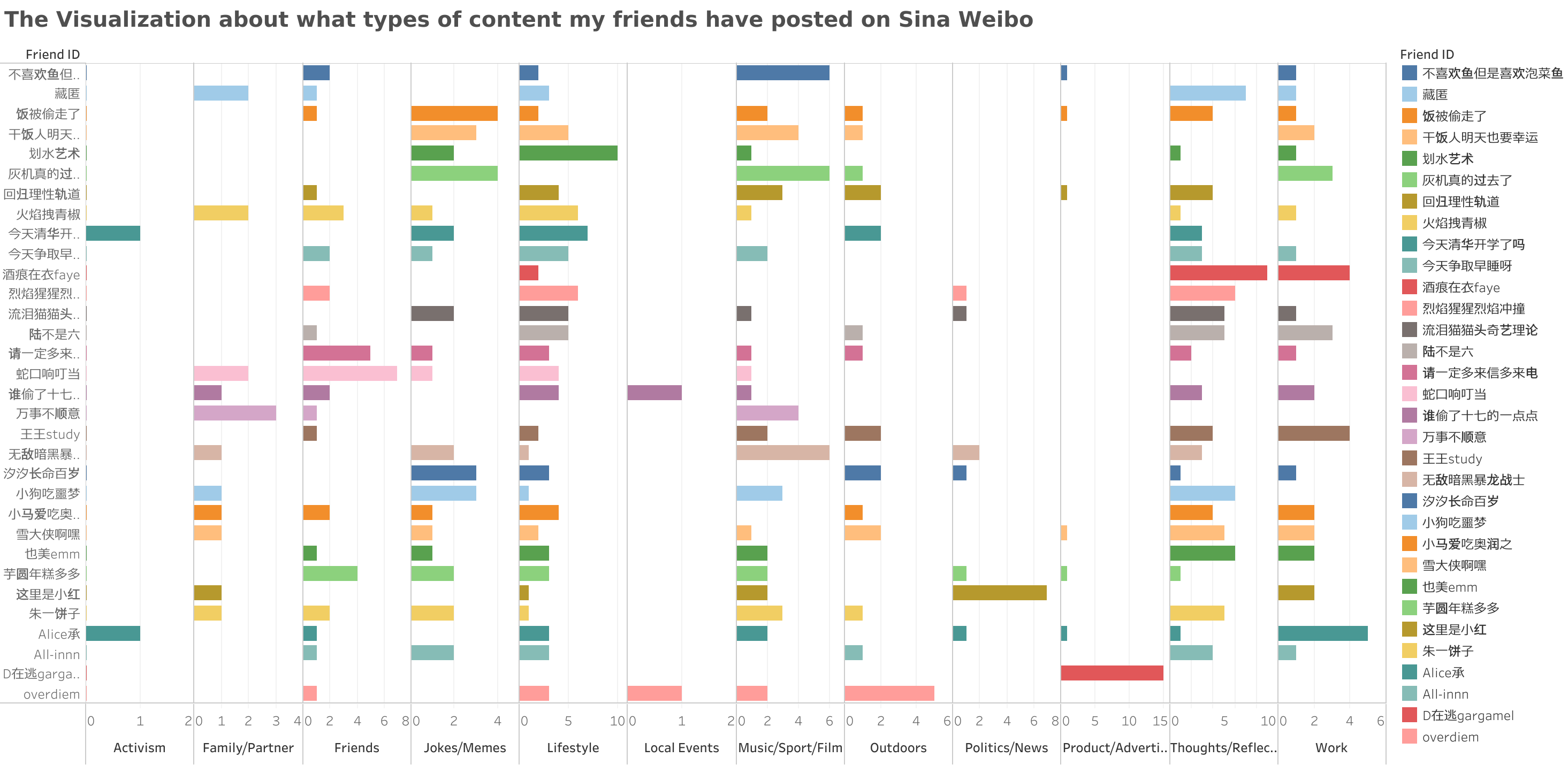
(Please do not use or leak the respondent’s information without authorization)
My Reflection
Sumpter suggests that we create several graphs with axes, plotting two of the categories against one another.
Although this method of visualization and analysis seems very clear, it takes up a lot of space.
Therefore, I used Tableau Public App to display the distribution characteristics of the last 15 posts of my thirty-two Weibo friends in terms of types in a three-dimensional bar chart that can include Friend ID, Types of Posts and The number of Posts.
Apart from the analyis method, I consider that Sumpter’s classification of content posted by Facebook and Instagram users is not suitable for Sina Weibo, especially in the actvism and politcs categories. China’s control of online public opinion is obviously more stringent than that in the UK and other Western countries. Therefore, when collecting my When looking at friend information, the frequency statistics in these two categories are very low. It may also be because of my friends themselves, but based on my own experience and feelings, I am more willing to focus on the national, political, social, and economic perspectives.
Raw Data